Easy to configure Google Analytics pipeline using SFTP
Published
June 5, 2023
Intro
Google Analytics has long been a trusted tool. But with a release of Google Analytics 4 (GA4) users face multiple challenges configuring and maintaining their operational insights available.
The migration effort is huge. And there are not many automation solutions for managing GA4 data either, because Admin and Data API are still being actively developed.
For data import GA4 offers only two import interfaces:
manual CSV upload
and SFTP (Secure File Transfer Protocol).
It seems quite strange and limiting choice compared to previously available Uploads API or other modern data integration options.
There are also not many comprehensive articles on how to migrate your pipelines. The best I’ve seen so far is from Ahmed Ali on SFTP to GA.
In this article, we will explore how to:
extend the pipeline to source the data from BigQuery to Google Analytics,
and automate configuration so that it takes just a few clicks.
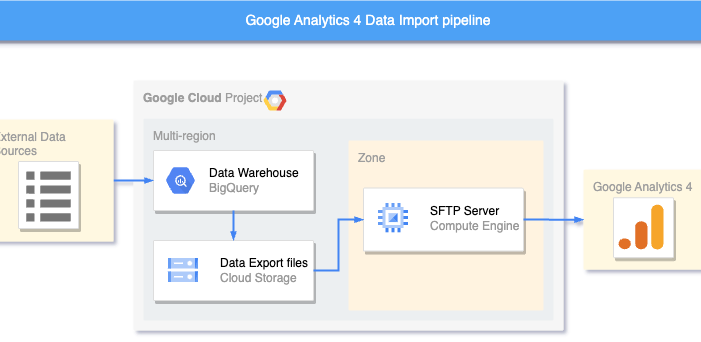
Architecture
Why SFTP?
GA4’s reliance on SFTP as the primary import interface stems from its focus on security and interoperability. By utilising SFTP, GA4 ensures a secure transfer of data between systems, reducing the risk of data breaches or unauthorised access. And at the same time it aligns with Google’s commitment to data privacy and protection, an aspect of utmost importance in today’s data-centric landscape.
What other existing interface could allow GA4 to import CSV data from arbitrate storages?
Google Cloud Storage as file system
Creating an SFTP Gateway in Google Cloud Platform (GCP) is an effective solution to bridge the gap between your data warehouse and GA4. The SFTP gateway may act as an intermediary, granting GA4 access to Google Cloud Storage (GCS) objects, where data exported from BigQuery resides. This setup allows for a seamless transfer of data from BigQuery to GA4, while maintaining the stringent security measures enforced by the SFTP protocol.
By mounting GCS, the SFTP server treats GCS buckets and objects as if they were part of the local file system. This allows users to interact with GCS data through standard SFTP operations.
To mount GCS, you can leverage various tools and libraries available, such as Cloud Storage FUSE. It interprets the forward slash character (“/”) in object names as a separator for directories, effectively organizing objects with a common prefix as files within the same directory structure.
Google Analytics 4 Data Import diagram
BigQuery to Cloud Storage
There are multiple ways of doing this. Let’s review some of the easiest ways to start.
Scheduled queries
To leverage the power of BigQuery, users can set up regular queries to extract data in the expected schema and export it to GCS. This process enables the transformation and preparation of data within BigQuery itself, ensuring the data exported to GA4 aligns with the desired format and structure.
Disadvantage: when using EXPORT DATA statement BigQuery will automatically do file partitioning and create multiple files in the destination Cloud Storage path. You must provide wildcard URI for destination.
It seems unlikely that Google Analytics will change that as current data source limit is 1GB - meaning single uploads are less then that and partitioning not required.
Cloud Workflows
We can quickly fix the limitation of scheduled queries by using a Cloud Workflow automation.
As in queries, we will provide:
a query to run
and a Cloud Storage destination to push the data to.
We can use a generic template for the workflow itself and pass these from a Cloud Scheduler job as runtime arguments.
This way we can define a workflow only once and a trigger for each table export.
GCP Workflow
Other data orchestration tools
If you are already using some data orchestration - it’s going to be easier to add this step there.
Mounted GCS to the SFTP server enhances the integration between BigQuery, GCS and GA4, enabling a smooth and efficient flow of data from BigQuery to GA4 for analysis and activation.
Once the data is exported to GCS, GA4 can fetch the data following a predefined schedule set in the data source configuration. This scheduled fetching mechanism ensures that GA4 stays up-to-date with the latest data available in GCS, maintaining data consistency and accuracy.
While GA4’s scheduling feature simplifies the process of keeping data synchronized, it is crucial to consider the frequency and timing of data fetches to strike the right balance between timely insights and resource utilization.
In conclusion, although GA4’s reliance on SFTP as the sole import interface may initially seem limited, it aligns with Google’s security-first approach. As GA4 advances, it is conceivable that Google will expand import interface options in the future, further enhancing the automation and flexibility of data integration within GA4.
Automation
As we would prefer to maintain control and focus on security - we’ll deploy everything ourselves in our GCP project.
You’ll need Google Cloud permissions:
create VM instance and manage network for it
create Cloud Storage buckets and set their permissions
create Cloud Workflows and Cloud Scheduler jobs (optional)
This is where we will look into how to implement these steps using Python code and Google Colab notebook.
So let’s list the steps end-to-end:
Run the notebook to get you Cloud Setup ready (SFTP server, Cloud Storage bucket, data export pipeline)
I automated most of the steps using ga4-data-import Python package Python library. Let’s go through each step in more detail.
1. SFTP server
Cloud Storage FUSE needs to be installed additionally to the instance to mount the Cloud Storage bucket.
We’ll need to create a dedicated system user to be used for SFTP authorisation. This user’s home directory will contain the mounted folder. Only this location to be set as a root location for SFTP access to restrict visibility of the rest of filesystem.
In order to allow only SFTP incoming traffic we can use the default-allow-ssh networking tag that whitelists port 22 for all incoming external traffic.
As the permissions for the instance itself (to be able to read from Cloud Storage, for example) we can use Compute Engine default service account (or you may create and specify a dedicated one).
The cheapest machine type available in GCP VMs will satisfy our requirements - so let’s start with f1-micro.
Show code
from ga4_data_import.compute import create_static_address, create_instancefrom ga4_data_import.storage import create_bucket, add_bucket_read_access# Reserve static IP for your serverINSTANCE_IP = create_static_address(GCP_PROJECT_ID, REGION, instance_name=INSTANCE_NAME)print(f"""Instance IP `{INSTANCE_IP}` is reserved in your project: https://console.cloud.google.com/networking/addresses/list?project={GCP_PROJECT_ID}""")instance = create_instance( instance_name=INSTANCE_NAME, project_id=GCP_PROJECT_ID, zone=ZONE, static_address=INSTANCE_IP, bucket_name=BUCKET_NAME, sftp_username=SFTP_USERNAME,)print(f"""SFTP server on a VM instance `{INSTANCE_NAME}` is available in your project: https://console.cloud.google.com/compute/instancesDetail/zones/{ZONE}/instances/{INSTANCE_NAME}?project={GCP_PROJECT_ID}""")print(f"""Now you can enter connection settings to Data Import UI: Server Username: {SFTP_USERNAME}""")
2. Mounted Cloud Storage bucket
In contrast to creating a Cloud Storage bucket mounting it is not a trivial task.
We’ll need to make sure that:
user home folder is owned by the root user
$ chown root:root /home/{sftp_username}
the bucket is mounted into a folder that has different name from the bucket (read more)
the --implicit-dirs flag is included if you plan to use other than root locations in the bucket (read more)
Show code
SERVICE_ACCOUNT_EMAIL = instance.service_accounts[0].emailcreate_bucket(BUCKET_NAME, REGION)add_bucket_read_access(BUCKET_NAME, SERVICE_ACCOUNT_EMAIL)print(f"""Bucket `{BUCKET_NAME}` linked to an SFTP server is available in your project: https://console.cloud.google.com/storage/browser/{BUCKET_NAME}?project={GCP_PROJECT_ID}""")
3. BigQuery data export to bucket
Our Scheduler job will define a cron syntax for a schedule, SQL to query the data and location in Cloud Storage where to store the exported files.
As each query result is stored in a temporary table, we’ll be using it an intermediate step. This way we can rely on all the processing done with native BigQuery operations.
We don’t need to “allow large results” for the query as it already covers the Google Analytics data import file size.
Show code
from ga4_data_import.workflow import deploy_workflow, deploy_schedulerWORKFLOW_ID ="BQ-to-GCS"SCHEDULER_ID ="Cost-Data-Export_at_8amUTC"SCHEDULE ="* 8 * * *"QUERY ="SELECT * FROM `max-ostapenko.Public.cost_data`"STORAGE_OBJECT ="cost_data.csv"deploy_workflow( GCP_PROJECT_ID, REGION, workflow_id=WORKFLOW_ID, service_account_email=SERVICE_ACCOUNT_EMAIL,)deploy_scheduler( GCP_PROJECT_ID, REGION, scheduler_id=SCHEDULER_ID, service_account_email=SERVICE_ACCOUNT_EMAIL, schedule=SCHEDULE, workflow_id=WORKFLOW_ID, query=QUERY, storage_path=f"gs://{BUCKET_NAME}/{STORAGE_OBJECT}",)print(f"""Workflow and trigger are deployed. Now you can test your data export: https://console.cloud.google.com/cloudscheduler?project={GCP_PROJECT_ID}""")
4. Data source in GA4
This step can’t be automated due to the lack of corresponding Admin API methods.
Looking at the level of detail of the existing admin operations available over API I expect these methods will become available later. So we’ll be able to create and fetch all the data source configurations, including public key.
For now let’s do it manually in the GA4 UI.
GA4 Data Source
Show code
print(f"""Now you can enter connection settings to Data Import UI: Server Username: {SFTP_USERNAME} Server url: sftp://{INSTANCE_IP}/{STORAGE_OBJECT}""")
5. Authorising GA4 public key
All the public key are stored as part of the VM instance metadata. So we can update it and verify in the instance details:
Public key on VM instance
Show code
from ga4_data_import.compute import add_server_pub_keyKEY_VALUE ="ssh-rsa AAA...ffE= Google Analytics Data Import Key"add_server_pub_key( GCP_PROJECT_ID, ZONE, instance_name=INSTANCE_NAME, pub_key=KEY_VALUE, username=SFTP_USERNAME,)print(f"""Public Key is added to your SFTP server. Now you can connect to your SFTP server with your private key.""")
Cost
Monthly expected cost of self-deployed solution can be verified in Google Cloud Pricing Calculator. It is still under USD 10.
Each additional property with 4 data sources, 10MB daily imports each increases it on ~20 cents.
There is no serverless version of SFTP so at some point you’ll need to use a more powerful machine type.
Advanced use cases
Multi-property usage
If you need to manage imports for several properties it could be done via single SFTP server.
For example, use partitioning in the object path: gs://bucket_name/{PROPERTY_ID}/{IMPORT_TYPE}.csv
and you will have corresponding SFTP URLs: sftp://{SFTP_ADDRESS}/{PROPERTY_ID}/{IMPORT_TYPE}.csv
Or if you need to separate data access along the data pipeline, match distinct permissions to particular GA property: